




















これからLoRAも紹介していくので、まず「LoRAとはどういう物か」解説から入ります。
LoRAとは
(Low-Rank Adaptation)を縮めてLoRAと呼び「低コストの追加学習」という意味です。
stable diffsionではまずイラスト生成に使う学習モデル「Stable Diffusion checkpoint」
を設定するのですが、この設定した学習モデルとは別で学習を行った物となります。
説明文だけだと少し複雑ですが、簡単に説明すると
「checkpointだけでは表現しきれない内容を追加した学習モデル」ですね。
銃の構えなど特定のポーズ、髪留めやメイクなど
プロンプトだけでは表しきれない表現や描画などを可能にしてくれます。
LoRAで出来る事
- 描画や質感を変える
- 服の柄や恰好、風景などの表現を特定の形に定める
- 前髪の掻き分け、顔の輪郭などキャラクターを再現する
- 構えや姿勢、物の持ち方など特定のポージングを可能にする
プロンプトだけのtxt 2 img生成では出来ない表現を幅広く実現可能ですが
まずは必要とするLoRA学習モデルを探す必要があります。
LoRAの探し方
オススメはcivitaiです。
civitaiは画像サムネイル付きでLoRAの効果を紹介してるので、
検索リストは少し長くなりますが目的の物や、予想外の発見があります。

検索一覧を引用してます。
左の検索タブで、LoRAと使用してるstable diffsionを選択します。
ページを開くと右上にダウンロードの記号があるので、DLした後にSD-WebUIをリスタートします。

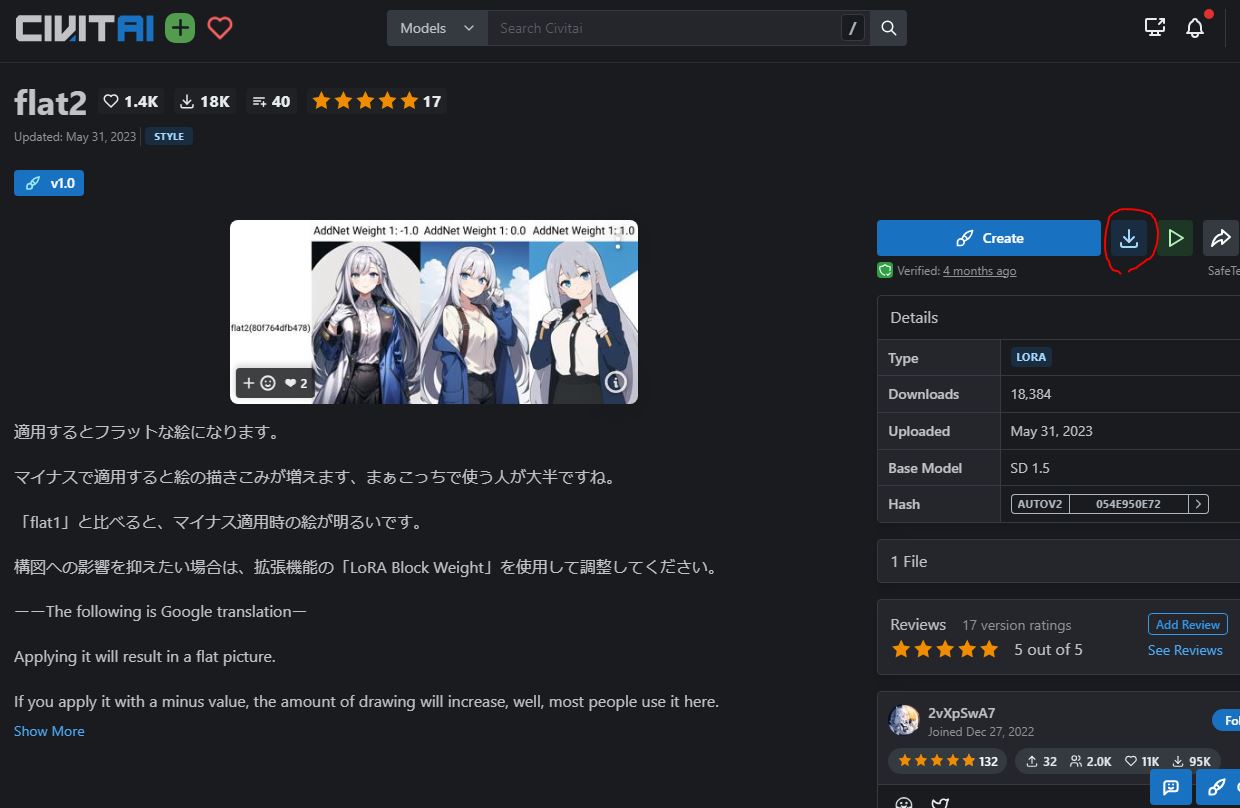
LoRAにはTrigger Wordsという「起動するために必要なプロンプトの入力」
が有る物もあるので、その記載についても確認しておきます。
2枚目の右側「base model」の下でTrigger Wordsの有無を確認できます。
LoRA学習モデルの保存先
stable diffusionのフォルダを開き、\models\LoRAに入れます(1枚目)
フォルダで分けるとSD-WebUI上でもタブで小分けされるので量が増えてくると便利です(2枚目)
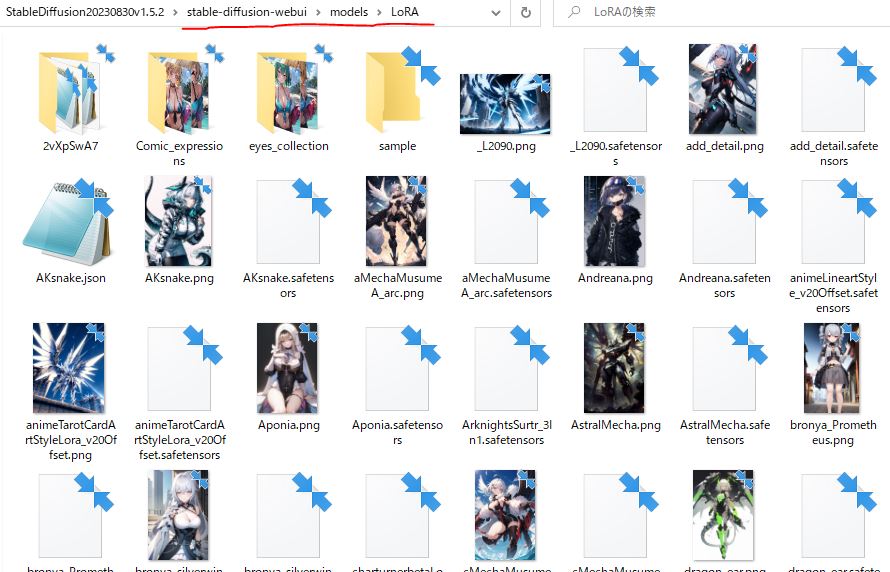

上記のように「LoRAの名前.png」で画像を置くとLoRAにアイコンを割り振る事が出来ます。
パッと見でどれがどのLoRAかを見分けれるので、
civitaiの配布元の画像を置いたり、自分で画像を選んで使いやすくしましょう。
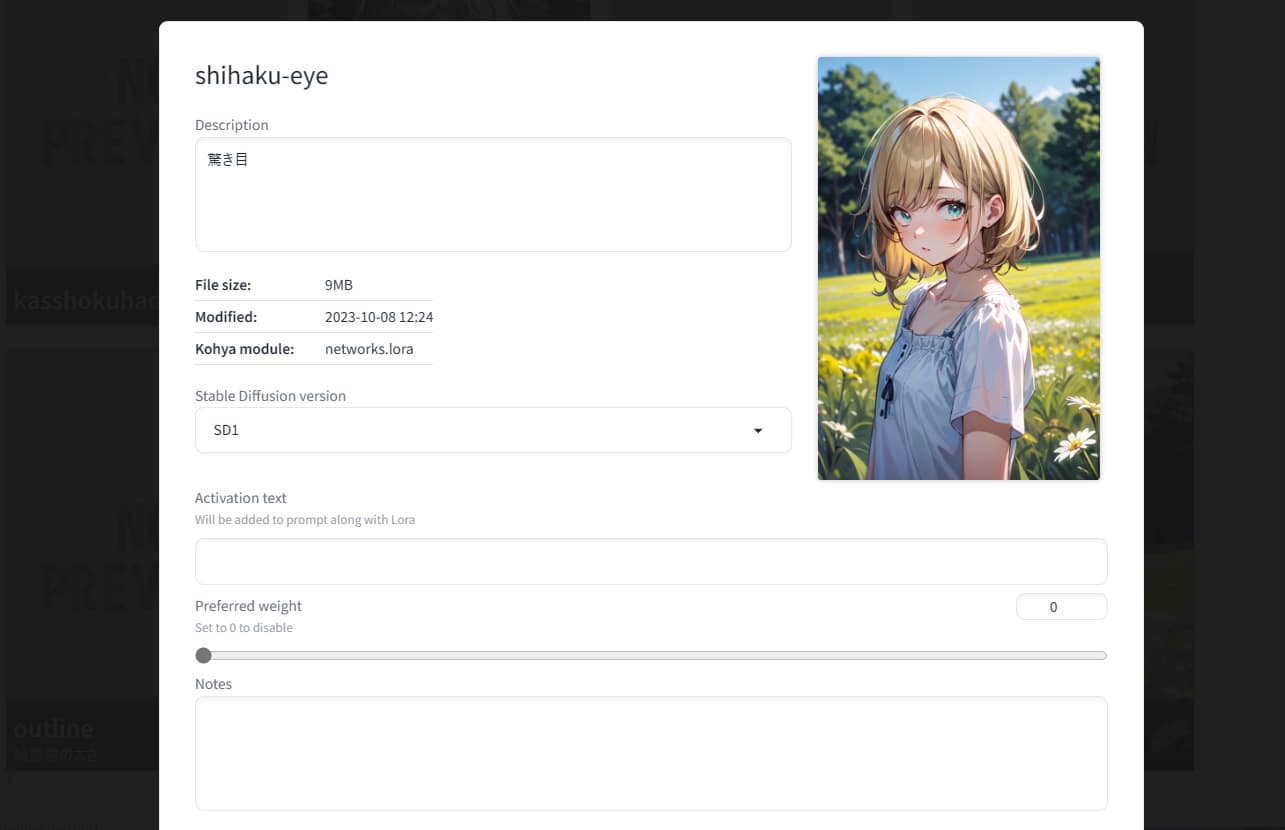
SD-WebUI上のLoRAの編集
SD-WebUIでのLoRAの一覧表示で、LoRAのサブタイトルを編集したり
先ほど紹介した「Trigger Word」を保存する事が出来ます。
マウスカーソルをLoRAに合わせると右上に編集マークが出るのでクリック。

上のDescriptionがサブタイトル。
Activation textがTrigger Wordやその他プロンプトを記憶させます。
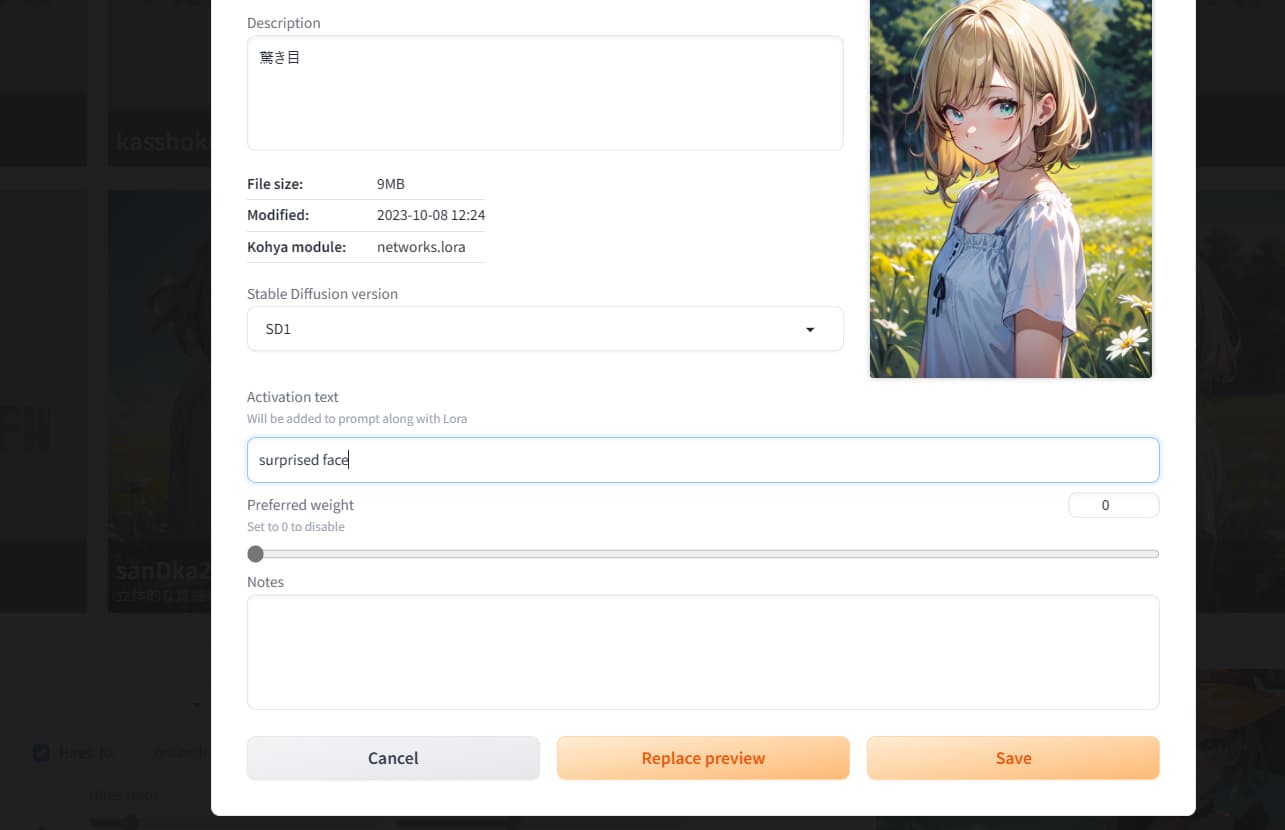
編集し終わったら右下のSaveを押して、編集画面の外の暗い部分や右上の×を押します。
最後に
LoRAは少し複雑ですが、扱えるようになるとモデルの限界に囚われない表現が可能になります。
今のモデルでは出来ない事や手が届かない所に取り入れて行きましょう。
次の記事ではLoRAの使い方とその拡張機能「lora block weight」を紹介します。

コメント